
In the rapidly evolving field of video generation, a groundbreaking framework called MultiTalk has emerged, pushing the boundaries of audio-driven multi-person conversational video creation. Developed by researchers from the Shenzhen Campus of Sun Yat-sen University, Meituan, and HKUST, MultiTalk addresses the challenges of generating realistic, audio-synchronized videos featuring multiple characters interacting based on a given prompt. This article explores the innovative features of MultiTalk, its technical advancements, and its potential applications, making it a must-read for tech enthusiasts, content creators, and AI developers.
What is MultiTalk?
MultiTalk is a novel framework designed for audio-driven multi-person conversational video generation, a new task introduced to overcome the limitations of existing single-person animation methods. Unlike traditional approaches that struggle with multi-stream audio inputs and incorrect audio-to-person binding, MultiTalk delivers seamless, high-quality videos where multiple characters’ lip movements and body gestures align perfectly with their respective audio streams. By leveraging advanced techniques like Label Rotary Position Embedding (L-RoPE) and a robust training strategy, MultiTalk sets a new standard for creating dynamic, interactive video content.
Key Features of MultiTalk
- Multi-Stream Audio Injection: MultiTalk supports multiple audio inputs, ensuring each character’s movements correspond accurately to their specific audio stream, avoiding common binding errors.
- Instruction-Following Capability: The framework excels at following text prompts, enabling precise control over character interactions and movements in the generated video.
- High-Quality Video Output: Built on the Wan2.1-12V-14B video diffusion model, MultiTalk produces vivid, realistic videos with resolutions up to 720p.
- Adaptive Person Localization: MultiTalk dynamically tracks multiple individuals in a video, ensuring accurate audio-to-person synchronization even with extensive movements.
- Long Video Generation: Using an autoregressive-based method, MultiTalk can generate extended video sequences, suitable for real-world applications like movie scenes or live streaming.
Technical Innovations Behind MultiTalk
MultiTalk’s superior performance stems from several cutting-edge technical advancements outlined in the research paper (arXiv:2505.22647v1):
1. Label Rotary Position Embedding (L-RoPE)
One of the core challenges in multi-person video generation is ensuring that each audio stream drives the correct character’s movements. MultiTalk introduces L-RoPE, a novel method that assigns unique labels to audio embeddings and video latents. This technique activates specific regions in the audio cross-attention map, effectively resolving incorrect binding issues. The ablation study in the research shows that L-RoPE maintains robust performance across different label ranges, enhancing its reliability.
2. Adaptive Person Localization
To handle dynamic scenes with multiple characters, MultiTalk employs an adaptive localization method. By analyzing the reference image and self-attention maps within the Diffusion-in-Transformer (DiT) architecture, the framework identifies and tracks each person’s position across video frames, ensuring precise audio-driven animation.
3. Audio Cross-Attention Mechanism
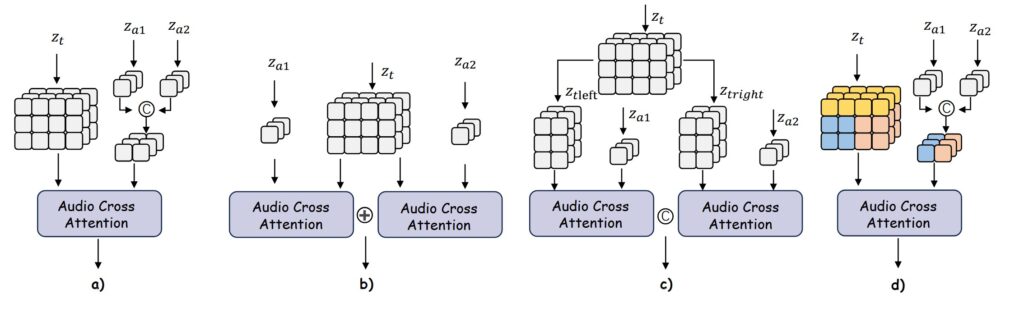
MultiTalk integrates an audio cross-attention layer into its DiT-based video diffusion model, using Wav2Vec for audio embedding extraction. This allows the model to synchronize lip movements and body gestures with audio cues, even in complex multi-person scenarios. An audio adapter compresses audio embeddings to align with the temporal compression of the 3D Variational Autoencoder (VAE), ensuring smooth frame-by-frame calculations.
4. Training Strategies
The framework employs a two-stage training process:

- Stage 1: Focuses on single-person animation using a 2,000-hour video dataset of talking heads and bodies.
- Stage 2: Enhances multi-person capabilities with 100 hours of dual-person conversation videos.
Additionally, partial parameter training (fine-tuning only the audio cross-attention layer and adapter) and multi-task training (combining audio + image-to-video and image-to-video tasks) preserve the model’s instruction-following ability, preventing degradation in motion and interaction quality.
Performance and Comparisons
MultiTalk was evaluated on multiple datasets, including HDTF, CelebV-HQ, EMTD, and a custom MTHM dataset for dual-human scenarios. The results, as shown in the research, demonstrate MultiTalk’s superiority over competing methods like AniPortrait, VExpress, EchoMimic, and Fantasy Talking. Key metrics include:
- Sync-C and Sync-D: Measures lip synchronization, where MultiTalk achieves scores like 8.53 (HDTF) and 8.34 (EMTD) for multi-person scenarios.
- E-FID: Evaluates facial expressiveness, with MultiTalk scoring 1.24 (HDTF) and 1.51 (EMTD).
- FID and FVD: Assesses video quality, with MultiTalk delivering competitive results (e.g., FID of 27.27 on HDTF).
Qualitative comparisons highlight MultiTalk’s ability to follow instructions accurately and generate artifact-free videos, outperforming methods that rely on video concatenation for multi-person scenarios.
Applications of MultiTalk
MultiTalk’s versatility makes it suitable for various applications:
- Entertainment: Create multi-character movie scenes or animated series with realistic conversations.
- E-Commerce: Enhance live-streaming experiences for e-retailers with virtual hosts.
- Education: Develop engaging, interactive video content for online learning platforms.
- Gaming: Generate dynamic NPC (non-player character) interactions in video games.
Limitations and Future Directions
While MultiTalk excels with real audio inputs, it performs less optimally with synthesized audio, as noted in the research. Future work aims to bridge this gap to improve facial expressiveness. Additionally, the framework’s computational requirements (e.g., 64 NVIDIA H800-80G GPUs for training) may pose challenges for smaller-scale deployments, though the open-source availability on GitHub (https://github.com/MeiGen-AI/MultiTalk) makes it accessible for academic exploration.
Societal Impacts and Ethical Considerations
MultiTalk offers immense potential for creative and commercial applications but raises concerns about misuse, such as generating fake celebrity videos. The researchers acknowledge this risk, emphasizing the need for responsible use to prevent misinformation.
How to Get Started with MultiTalk
MultiTalk is available under the Apache 2.0 license for academic use, with code, weights, and documentation on GitHub. A Gradio demo on Hugging Face allows users to experiment with the framework, while integration with ComfyUI via WanVideoWrapper simplifies workflows. Note that high-resolution (720p) inference requires multiple GPUs, and the current wrapper has limited support for multi-person scenarios.
For developers and researchers, MultiTalk provides a robust starting point for building advanced video generation tools. Check out the official repository for setup instructions and sample code.
Conclusion
MultiTalk represents a significant leap forward in audio-driven multi-person conversational video generation. Its innovative L-RoPE method, adaptive localization, and strategic training approaches make it a powerful tool for creating high-quality, interactive videos. Whether you’re a content creator, educator, or AI enthusiast, MultiTalk opens up exciting possibilities for the future of video generation.
Explore MultiTalk today and unlock the potential of dynamic, audio-driven storytelling!
