
The field of video generation has seen remarkable advancements in recent years, with autoregressive diffusion models pushing the boundaries of what’s possible. Among the latest breakthroughs is Self-Forcing Video Generation, a novel approach that bridges the gap between training and inference in autoregressive video diffusion, delivering high-quality, real-time video synthesis. This article dives into the technical underpinnings, practical applications, and transformative potential of Self-Forcing for both professionals and enthusiasts in AI-driven content creation.
Understanding Self-Forcing Video Generation
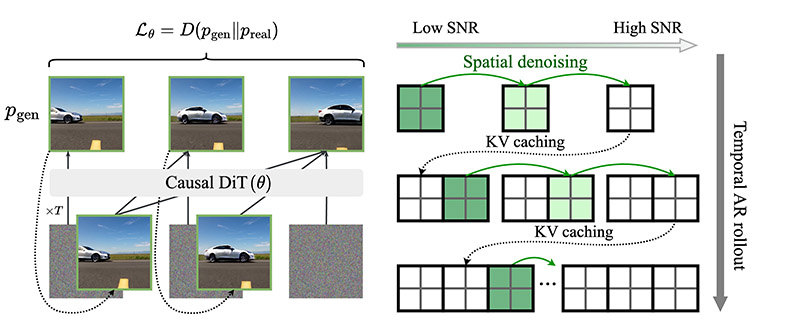
At its core, Self-Forcing is a training paradigm designed to address the exposure bias problem in autoregressive video diffusion models. Exposure bias occurs when a model, trained on ground-truth data, struggles during inference because it must rely on its own imperfect predictions, leading to cumulative errors over time. Self-Forcing mitigates this by aligning the training process with inference conditions, ensuring models generate coherent and high-fidelity video sequences.
Key Mechanism: Autoregressive Rollout with KV Caching
Self-Forcing introduces an autoregressive rollout during training, where the model generates subsequent frames based on its own previously generated frames, rather than ground-truth data. To make this computationally feasible, Self-Forcing leverages Key-Value (KV) caching, a technique that stores intermediate computations to avoid redundant processing. This enables efficient training and inference, allowing the model to generate video frames in a streaming fashion at approximately 10-16 frames per second (FPS) with a low initial latency of around 0.8 seconds on consumer-grade GPUs like the NVIDIA RTX 4090.
Holistic Video-Level Loss
Unlike traditional frame-by-frame optimization, Self-Forcing employs a holistic video-level loss. This loss function evaluates the quality of the entire generated video sequence, ensuring temporal coherence and alignment with the distribution of real-world videos. By optimizing for the full sequence, Self-Forcing produces videos that maintain consistent motion, identity preservation, and visual fidelity across frames.
Technical Advantages
Self-Forcing stands out for its efficiency and performance, making it a game-changer for real-time video generation. Here are its key technical advantages:
- Few-Step Diffusion: Self-Forcing uses a streamlined diffusion process with fewer sampling steps, reducing computational overhead while maintaining high-quality outputs. This makes it suitable for real-time applications where speed is critical.
- Gradient Truncation: To further optimize training, Self-Forcing employs gradient truncation strategies, which prevent excessive memory usage and enable scalability on consumer hardware.
- Streaming Capability: By generating frames sequentially with low latency, Self-Forcing supports streaming applications, such as live video synthesis for gaming, virtual environments, or interactive media.
- Keyframe-Guided Generation: Self-Forcing excels at generating videos from sparse keyframes (e.g., a starting and ending image) combined with text prompts. This allows creators to define the narrative arc while the model fills in smooth, coherent transitions.
Practical Applications
Self-Forcing Video Generation has a wide range of applications for both professionals and enthusiasts:
- Content Creation: Filmmakers and animators can use Self-Forcing to generate dynamic video sequences from text prompts and keyframes, streamlining pre-visualization and storyboarding workflows.
- Gaming and Virtual Reality: Real-time video synthesis enables immersive environments where dynamic scenes adapt to player inputs or narrative changes.
- Advertising and Marketing: Marketers can create personalized, high-quality video ads with minimal manual effort, leveraging text prompts to tailor content to specific audiences.
- AI Research: Researchers can explore Self-Forcing as a foundation for advancing autoregressive diffusion models, particularly in domains requiring temporal consistency, such as video prediction or simulation.
Example Use Case
Imagine a content creator tasked with producing a promotional video. Using a prompt like, “A futuristic cityscape at dusk with flying cars and neon lights”, and providing a starting keyframe of a city skyline and an ending keyframe of a close-up on a sleek vehicle, Self-Forcing can generate a smooth, 5-second video clip. The model ensures consistent lighting, coherent motion of vehicles, and preservation of the city’s aesthetic, all rendered in real-time.
Implementation and Tools
Self-Forcing has been integrated into accessible tools like ComfyUI, a popular platform for AI-driven content creation. The Wan Video Wrapper node in ComfyUI implements Self-Forcing, allowing users to experiment with video generation using pre-trained models. These tools democratize access, enabling both professionals with robust hardware and enthusiasts with consumer GPUs to explore the technology.
Sample Workflow in ComfyUI
- Input Keyframes: Upload a starting and ending frame to define the video’s narrative.
- Text Prompt: Provide a descriptive text prompt to guide the model’s style and content.
- Configure Model: Select a Self-Forcing-enabled model (e.g., based on the research framework from Adobe and UT Austin).
- Generate Video: Run the model to produce a video sequence, tweaking parameters like frame rate or duration as needed.
Limitations and Future Directions
While Self-Forcing is a significant leap forward, it has some limitations:
- Extrapolation Challenges: Videos longer than the training duration (e.g., >5 seconds) may exhibit quality degradation. Techniques like sliding window extrapolation help mitigate this by generating videos in overlapping segments.
- Hardware Dependency: While optimized for consumer GPUs, performance scales with hardware capabilities, and lower-end systems may struggle with real-time generation.
- Fine-Tuning Needs: Achieving domain-specific results (e.g., hyper-realistic human faces) may require additional fine-tuning of pre-trained models.
Future research is likely to focus on extending video duration, improving robustness for diverse content types, and integrating Self-Forcing with other generative paradigms, such as multimodal diffusion or reinforcement learning.
Why It Matters
Self-Forcing Video Generation represents a paradigm shift in how we approach video synthesis. By addressing exposure bias and enabling real-time, high-fidelity video generation, it empowers creators to produce dynamic content with unprecedented ease and efficiency. For professionals, it’s a tool to accelerate workflows and push creative boundaries. For enthusiasts, it’s an accessible entry point into the world of AI-driven video creation.
Getting Started
To explore SELF-Forcing, check out the original research paper, “Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion” (arXiv:2506.08009), published by Adobe and the University of Texas at Austin in 2025. For hands-on experimentation, platforms like ComfyUI offer a practical starting point. Whether you’re a seasoned AI researcher or a creative enthusiast, Self-Forcing opens up exciting possibilities for the future of video generation.
Vset3D 2025 virtual production software
