Exploring π³: A Breakthrough in Visual Geometry Learning
Introduction
In the rapidly evolving field of computer vision, a new approach called π³ (Pi Cube) has emerged, redefining how neural networks reconstruct visual geometry. Developed by a team of researchers, π³ introduces an innovative method that eliminates the need for a fixed reference view, a common limitation in both traditional and modern approaches. In this article, we explore the workings of π³, its advantages, disadvantages, and potential impact on applications such as augmented reality, robotics, and autonomous navigation, all from a critical reviewer’s perspective.
What is π³?
π³ is a feed-forward neural network designed for geometric reconstruction from images, whether from a single image, video sequences, or unordered image sets. Unlike conventional methods like Structure-from-Motion (SfM) or Multi-View Stereo (MVS), which rely on a fixed reference view to establish a global coordinate system, π³ employs a fully permutation-equivariant architecture. This means the order of input images does not affect the results, marking a significant advancement in robustness and scalability for 3D vision models.
How π³ Works
The operation of π³ is built on several key principles:
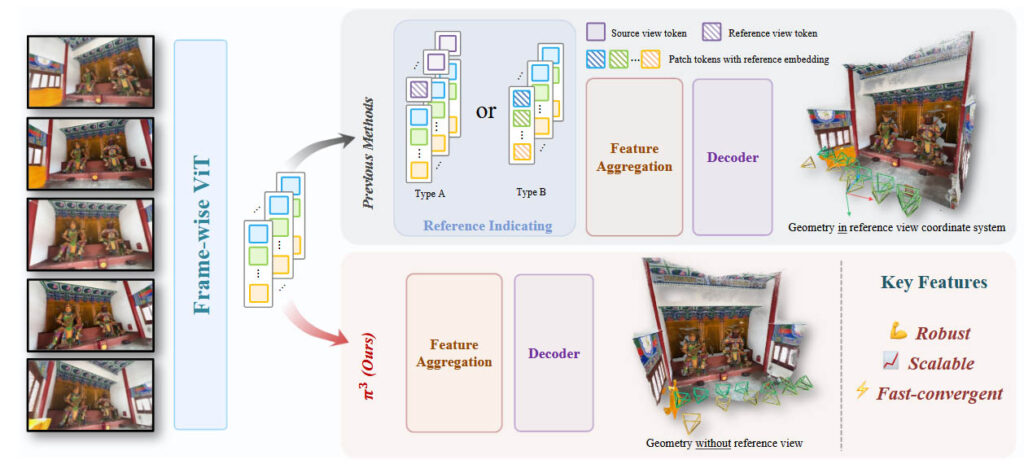
- Permutation Equivariance: π³ eliminates the need for a reference view by predicting affine-invariant camera poses and scale-invariant local point maps, all relative to each image’s own coordinate system. This ensures consistent results regardless of input order.
- Transformer Architecture: The model uses a transformer architecture with alternating view-wise and global self-attention, similar to VGGT, but without order-dependent components like frame index positional embeddings.
- Relative Predictions: π³ predicts camera poses and point maps for each image without requiring a global reference frame, making it immune to arbitrary view selection biases.
- Two-Stage Training: The model is trained in two phases: first at a low resolution (224×224 pixels), then fine-tuned at varied resolutions with a dynamic batch sizing strategy. Initial weights are sourced from a pre-trained VGGT model, with the encoder frozen during training.
Practical Applications
π³ excels in several computer vision tasks, including:
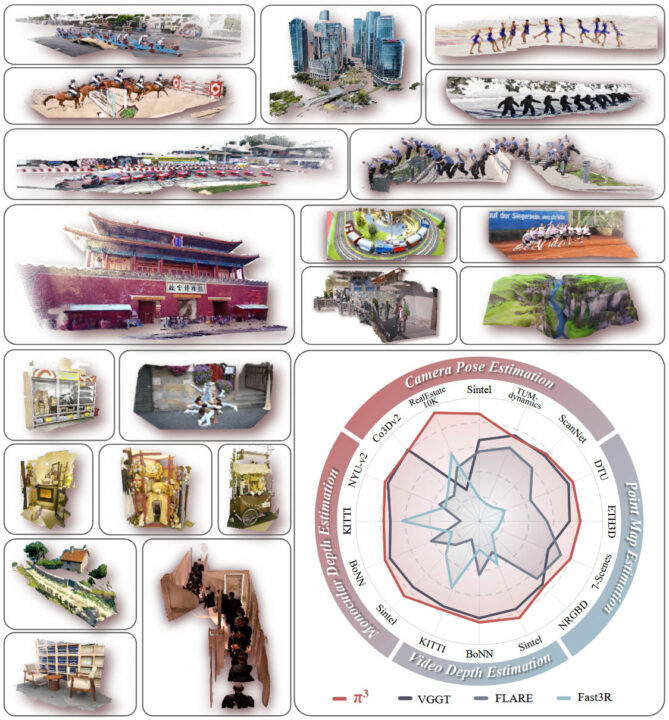
- Camera Pose Estimation: On benchmarks like RealEstate10K and Sintel, π³ significantly reduces translation and rotation errors compared to methods like VGGT.
- Monocular and Video Depth Estimation: π³ outperforms models like MoGe and VGGT in absolute relative error, with impressive efficiency (57.4 FPS on KITTI).
- Dense Point Map Reconstruction: On datasets like DTU and ETH3D, π³ produces more accurate and consistent reconstructions, even in sparse-view scenarios.

Advantages of π³
As a reviewer, several aspects of π³ stand out as particularly impressive:
- Robustness to Input Order: Its permutation-equivariant design eliminates biases tied to reference view selection, a common issue in traditional approaches. Tests show near-zero variance in reconstruction metrics, even when input image order varies.
- Scalability: π³ demonstrates consistent performance improvements with increasing model size, as observed in tests with Small (196.49M parameters), Base (390.13M), and Large models.
- Fast Convergence: The model converges more quickly than non-equivariant baselines, reducing training time while maintaining high accuracy.
- Computational Efficiency: With an inference speed of 57.4 FPS on KITTI, π³ surpasses competitors like VGGT (43.2 FPS) and Dust3R (1.2 FPS) while being lightweight.
- Versatility: π³ handles both static and dynamic scenes effectively, making it suitable for a wide range of applications, from augmented reality to autonomous navigation.
Disadvantages and Limitations
Despite its advancements, π³ has some limitations that warrant consideration:
- Transparent Objects: The model does not account for complex light transport phenomena, limiting its ability to handle transparent or reflective objects.
- Fine Details: Compared to diffusion-based approaches, π³ produces less detailed geometric reconstructions, which may hinder applications requiring extreme precision.
- Grid-like Artifacts: Point cloud generation relies on a simple upsampling mechanism (MLP with pixel shuffling), which can introduce noticeable grid-like artifacts, especially in high-uncertainty regions.
- Training Data Dependency: While robust, π³’s performance still depends on the quality and diversity of training data, particularly for real-world “in-the-wild” scenarios.
Comparison with Existing Methods

Compared to methods like VGGT and Dust3R, π³ stands out for its lack of reliance on a reference view and its robustness to input order. Tests on datasets like Sintel, KITTI, DTU, and ETH3D show that π³ outperforms these methods in accuracy and efficiency while maintaining significantly lower variance in results. For example, on Sintel, π³ reduces camera pose translation error from 0.16 (VGGT) to 0.074 and video depth absolute relative error from 0.29 to 0.23.
Conclusion
π³ permutation-equivariant architecture eliminates a fundamental inductive bias, offering unmatched robustness and scalability. While limitations remain, particularly for transparent objects and fine details, π³’s performance across diverse benchmarks and its computational efficiency make it a promising tool for practical applications. For researchers and developers in computer vision, π³ paves the way for more stable and versatile 3D vision systems.