Artificial intelligence continues to transform how we interact with visual data, and the LLMDet-demo, created by Daniel Bourke (mrdbourke) on Hugging Face, is a prime example of this innovation. This interactive demo, hosted at Hugging Face Spaces, showcases the power of LLMDet, an open-vocabulary object detector that leverages large language models to identify objects in images with remarkable flexibility. Whether you’re a machine learning enthusiast, a developer, or simply curious about AI, this demo offers a hands-on way to explore cutting-edge computer vision technology. Let’s dive into what makes LLMDet-demo a must-try project.
What is LLMDet-Demo?
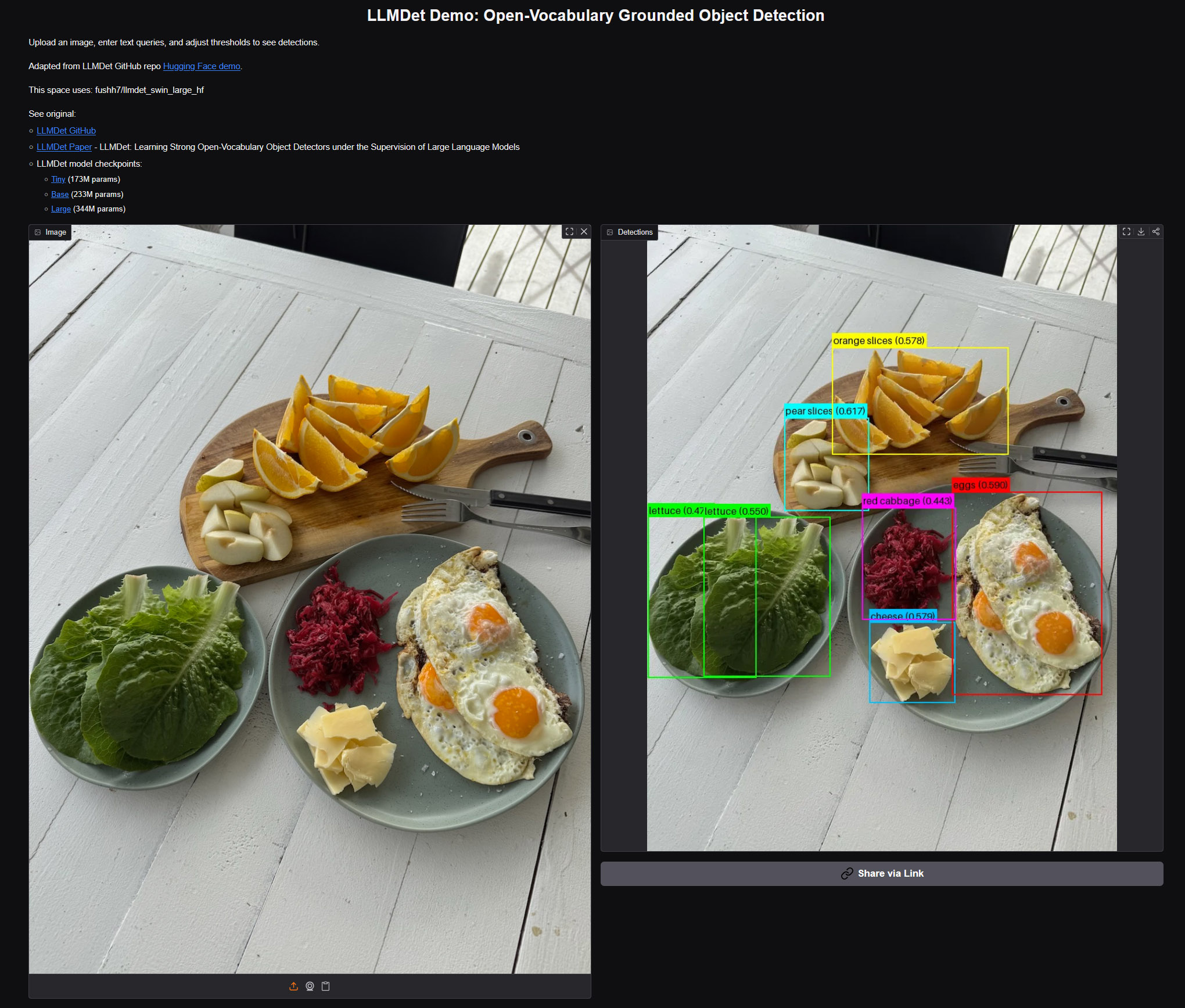
The LLMDet-demo is an interactive application built on Hugging Face Spaces, demonstrating the capabilities of LLMDet, a PyTorch-based open-vocabulary object detection model developed by Shenghao Fu and colleagues. Unlike traditional object detectors limited to predefined categories, LLMDet uses a large language model to generate detailed captions and grounding labels, enabling it to detect a wide range of objects based on free-form text prompts. The demo allows users to upload images, input text queries, and visualize detected objects with bounding boxes and labels, making it an accessible tool for exploring advanced AI.
As described in the original paper, LLMDet is fine-tuned with a dataset called GroundingCap-1M, which pairs images with detailed captions and grounding labels. This approach enhances the model’s ability to understand complex scenes, outperforming baseline models like MM-Grounding-DINO. The demo, built with Gradio, provides a user-friendly interface to test LLMDet’s capabilities in real time.
Key Features of LLMDet-Demo

1. Open-Vocabulary Detection
LLMDet’s standout feature is its ability to detect objects beyond fixed categories. Users can input custom text prompts (e.g., “red car” or “person holding a phone”), and the model identifies matching objects in the uploaded image, drawing precise bounding boxes around them.
2. Interactive Gradio Interface
The demo uses Gradio, a Python SDK supported by Hugging Face, to create a seamless user experience. Upload an image, enter a prompt, and instantly see the results with labeled bounding boxes. The interface is intuitive, requiring no coding knowledge to use.
3. High-Performance Model
LLMDet is fine-tuned from MM-Grounding-DINO and trained with objectives like grounding loss and caption generation loss. It achieves superior performance on benchmarks like LVIS, making it a robust choice for real-world applications. Pre-trained checkpoints (Swin-T, Swin-B, Swin-L) are available for developers to extend the model.
4. Visualization and Output
The demo visualizes detected objects with clear bounding boxes and labels, helping users understand the model’s predictions. Results can be downloaded or shared, making it ideal for presentations or collaborative projects.
5. Open-Source Accessibility
The underlying LLMDet code is available on GitHub under an Apache 2.0 license, encouraging community contributions. The Hugging Face Space also allows users to duplicate the demo for custom experiments.
How to Use LLMDet-Demo
Getting started with the LLMDet-demo is simple:
- Visit the Hugging Face Space.
- Upload an image (e.g., a photo of a street scene or indoor setting).
- Enter a text prompt describing the objects you want to detect (e.g., “dog” or “blue backpack”).
- Click “Submit” to run the model and view the results, which include bounding boxes and labels overlaid on the image.
- Optionally, download the output or adjust the prompt for further exploration.
For developers, the LLMDet GitHub repository provides scripts for training and evaluation. You can run inference with commands like:
bash dist_test.sh configs/grounding_dino_swin_t.py tiny.pth 8
This flexibility makes it easy to integrate LLMDet into custom pipelines or extend its functionality.
Why LLMDet-Demo Matters
The LLMDet-demo exemplifies the democratization of AI through open-source tools. By hosting the demo on Hugging Face, Daniel Bourke aligns with the platform’s mission to advance AI through open science. The project not only showcases a state-of-the-art model but also makes it accessible to a broad audience, from hobbyists to researchers.
Practical applications include:
- Retail and E-Commerce: Identify products in user-uploaded images for enhanced search or recommendation systems.
- Autonomous Systems: Enable robots or drones to recognize objects in dynamic environments.
- Content Moderation: Detect specific objects in images for automated filtering.
- Education: Serve as a learning tool for students exploring computer vision and large language models.
Technical Deep Dive
LLMDet’s innovation lies in its co-training approach, combining a grounding loss (for precise object localization) and a caption generation loss (for rich scene understanding). The GroundingCap-1M dataset, with 1 million images and detailed captions, empowers the model to handle diverse scenarios. The demo likely uses a lightweight checkpoint (e.g., Swin-T) to ensure fast inference on Hugging Face’s free CPU instances, balancing performance and accessibility.
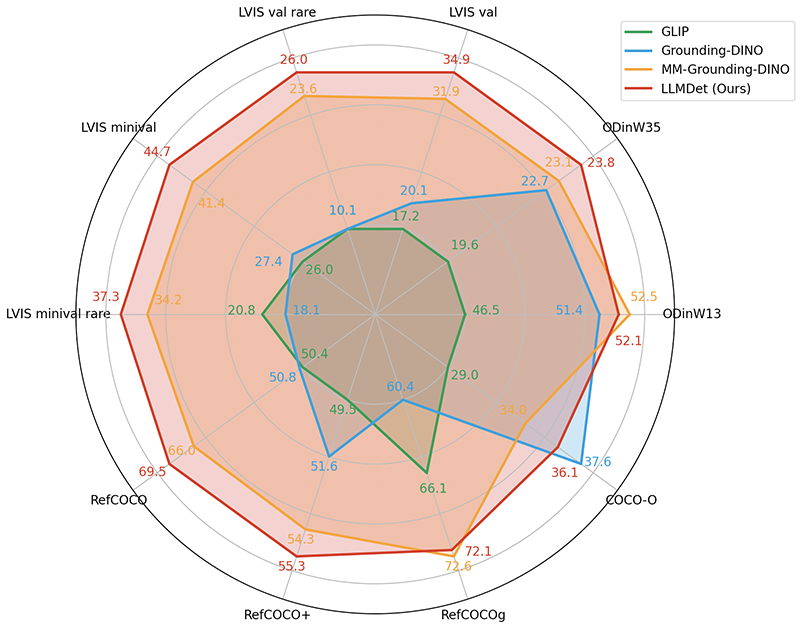
The model’s architecture builds on MM-Grounding-DINO, incorporating large language model supervision to generate region