
The world of artificial intelligence is evolving at an unprecedented pace, and ByteDance’s Seed team has just raised the bar with the release of BAGEL-7B-MoT, an open-source multimodal foundation model that redefines what AI can achieve. With 7 billion active parameters (14 billion total), BAGEL seamlessly integrates text-to-image generation, advanced image editing, and multimodal understanding into a single, unified model. This groundbreaking innovation, licensed under Apache 2.0, is set to empower developers, researchers, and creators worldwide. Let’s dive into what makes BAGEL a game-changer in the AI landscape.
What is BAGEL-7B-MoT?
BAGEL, developed by ByteDance Seed, is a decoder-only multimodal model pretrained on trillions of interleaved tokens from diverse data sources, including text, images, videos, and web content. Unlike traditional AI models that rely on separate systems for specific tasks—like DALL-E for image generation or GPT-4V for image understanding—BAGEL unifies these capabilities into one efficient framework. Its Mixture-of-Transformer-Experts (MoT) architecture, combined with dual encoders (Variational Autoencoder and Vision Transformer), enables it to process both pixel-level and semantic-level image features, delivering exceptional performance across a range of tasks.
Key Capabilities
BAGEL-7B-MoT stands out for its versatility and advanced functionality, including:
- Text-to-Image Generation: Creates high-quality images from text prompts, rivaling specialist models like Stable Diffusion 3 (SD3). With Chain-of-Thought (CoT) reasoning enabled, BAGEL achieves a GenEval score of 0.88, outperforming competitors like Janus-Pro-7B (0.80) and SD3-Medium (0.74).
- Image Editing: Supports free-form editing, style transfer, scene reconstruction, and multiview synthesis, often delivering more accurate results than leading open-source models like Flux.
- Image Understanding: Excels in visual understanding benchmarks, scoring 2388 on MME, 85.0 on MMBench, and 73.1 on MathVista, surpassing top-tier open-source Vision Language Models (VLMs) like Qwen2.5-VL and InternVL-2.5.
- Complex Multimodal Reasoning: Demonstrates emerging capabilities like future frame prediction, 3D manipulation, and world navigation, pushing the boundaries of “world-modeling” tasks.
- Chain-of-Thought Reasoning: Enhances performance by “thinking” through complex tasks step-by-step, making it ideal for sophisticated editing and reasoning scenarios.
These capabilities emerged naturally during BAGEL’s training, with basic understanding and generation appearing early, followed by editing, and finally advanced “intelligent editing” that requires deep visual reasoning. This staged progression highlights the power of scaling with rich, interleaved multimodal data.
Technical Architecture
BAGEL’s innovative design is built on a Mixture-of-Transformer-Experts (MoT) architecture, which optimizes performance by selectively activating modality-specific parameters. The model employs two separate encoders:
- Variational Autoencoder (VAE): Derived from FLUX.1-schnell, it ensures high-quality visual outputs.
- Vision Transformer (ViT): Provides robust semantic context for tasks requiring deep understanding.
This dual-encoder approach, combined with the Next Group of Token Prediction paradigm, allows BAGEL to maximize its capacity to learn from diverse multimodal data. The model was fine-tuned from Qwen2.5-7B-Instruct and siglip-so400m-14-384-flash-attn2, with supervised fine-tuning on specific datasets to boost benchmark performance.
Performance and Benchmarks
BAGEL-7B-MoT has been rigorously tested against industry-standard benchmarks, showcasing its superiority in both understanding and generation tasks:
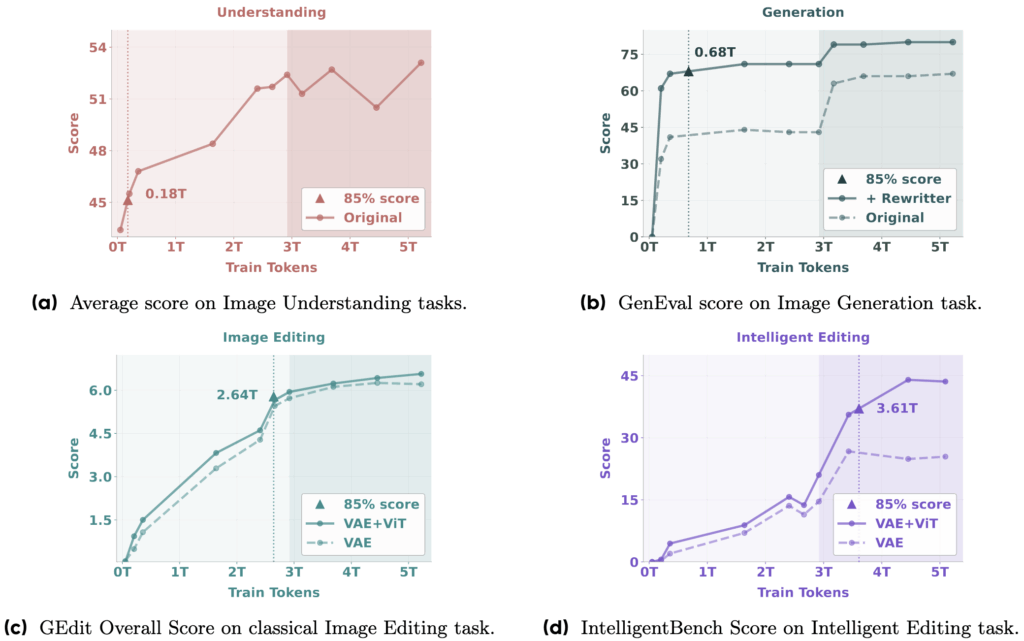
- Visual Understanding:
- MME: 2388
- MMBench: 85.0
- MMMU: 55.3
- MM-Vet: 67.2
- MathVista: 73.1
- Text-to-Image Generation:
- GenEval (with CoT): 0.88
- WISE (with CoT): 0.70
These scores position BAGEL as a leader among open-source VLMs, often outperforming models like Qwen2.5-VL and InternVL-2.5, while holding its own against proprietary systems like OpenAI’s GPT-4o.
Getting Started with BAGEL
Ready to explore BAGEL’s capabilities? The model is freely available under the Apache 2.0 license, with weights hosted on Hugging Face and code accessible via GitHub.
- For GPUs with 24GB VRAM (e.g., RTX 3090 or 4090), NF4 quantization is recommended. For 40GB+ VRAM (e.g., A100/H100), full precision is ideal. Check the GitHub repository for detailed instructions and quantized versions like BAGEL-7B-MoT-INT8 or FP8 for lower VRAM setups.
Limitations and Community Feedback
While BAGEL is a powerhouse, it’s not without limitations. Complex editing instructions may occasionally produce artifacts or misinterpretations, and the model requires significant computational resources (24GB+ VRAM recommended). ByteDance encourages community feedback to refine the model, with issues trackable via GitHub or discussions on the BAGEL Discord channel.
Why BAGEL Matters
BAGEL-7B-MoT is more than just a model—it’s a step toward democratizing AI. By releasing it as open-source, ByteDance empowers the global AI community to innovate without proprietary restrictions. Its ability to handle diverse tasks in a single model reduces complexity and opens new possibilities for applications in creative design, content generation, and multimodal reasoning. Whether you’re a developer building AI-driven apps or a researcher exploring the frontiers of multimodal AI, BAGEL offers unparalleled flexibility and performance.
Explore BAGEL Today
Ready to experience BAGEL’s capabilities firsthand? Visit the project website for an overview, try the demo, or dive into the research paper for a deep dive into its architecture and training. With BAGEL-7B-MoT, the future of multimodal AI is open, accessible, and full of potential.